
AIX disk queue depth tuning for performance
Purpose
The purpose of this document is to describe how IOs are queued with SDD, SDDPCM, the disk device driver and the adapter device driver, and to explain how these can be tuned to increase performance. This information is also useful for non-SDD or SDDPCM systems.
Where this stuff fits in the IO stack
Following is the IO stack from the application to the disk:
Application
File system (optional)
LVM (optional)
SDD or SDDPCM or other multi-path driver (if used)
hdisk device driver
adapter device driver
interconnect to the disk
Disk subsystem
Disk
Note that even though the disk is attached to the adapter, the hdisk driver code is utilized before the adapter driver code. So this stack represents the order software comes into play over time as the IO traverses the stack.
Why do we need to simultaneously submit more than one IO to a disk?
This improves performance. And this would be performance from an applications point of view. This is especially important with disk subsystems where a virtual disk (or LUN) is backed by multiple physical disks. In such a situation, if we only could submit a single IO at a time, we'd find we get good IO service times, but very poor thruput. Submitting multiple IOs to a physical disk allows the disk to minimize actuator movement (using an "elevator" algorithm) and get more IOPS than is possible by submitting one IO at a time. The elevator analogy is appropriate. How long would people be waiting to use an elevator if only one person at a time could get on it? In such a situation, we'd expect that people would wait quite a while to use the elevator (queueing time), but once they got on it, they'd get to their destination quickly (service time).
Where are IOs queued?
As IOs traverse the IO stack, AIX needs to keep track of them at each layer. So IOs are essentially queued at each layer in the IO stack. Generally, some number of in flight IOs may be issued at each layer and if the number of IO requests exceeds that number, they reside in a wait queue until the required resource becomes available. So there is essentially an "in process" queue and a "wait" queue at each layer (SDD and SDDPCM are a little more complicated).
At the file system layer, file system buffers limit the maximum number of in flight IOs for each file system. At the LVM layer, hdisk buffers limit the number of in flight IOs. At the SDD layer, IOs are queued if the dpo device's attribute, qdepth_enable, is set to yes (which it is by default). Some releases of SDD do not queue IOs so it depends on the release of SDD. SDDPCM on the other hand does not queue IOs before sending them to the disk device driver. The hdisks have a maximum number of in flight IOs that's specified by it's queue_depth attribute. And FC adapters also have a maximum number of in flight IOs specified by num_cmd_elems. The disk subsystems themselves queue IOs and individual disks can accept multiple IO requests. Here are an ESS hdisk's attributes:

The default queue_depth is 20, but can be changed to as high as 256 for ESS, DS6000 and DS8000.
Here's a FC adapter's attributes:

The default queue depth (num_cmd_elems) for FC adapters is 200 but can be increased up to 2048.
Here's the dpo device's attributes for one release of SDD:

When qdepth_enable=yes, SDD will only submit queue_depth IOs to any underlying hdisk (where queue_depth here is the value for the underlying hdisk's queue_depth attribute). When qdepth_enable=no, SDD just passes on the IOs directly to the hdisk driver. So the difference is, if qdepth_enable=yes (the default), IOs exceeding the queue_depth will queue at SDD, and if qdepth_enable=no, then IOs exceed the queue_depth will queue in the hdisk's wait queue. In other words, SDD with qdepth_enable=no and SDDPCM do not queue IOs and instead just pass them to the hdisk drivers. Note that at SDD 1.6, it's preferable to use the datapath command to change qdepth_enable, rather than using chdev, as then it's a dynamic change, e.g., datapath set qdepth disable will set it to no. Some releases of SDD don't include SDD queueing, and some do, and some releases don't show the qdepth_enable attribute. Either check the manual for your version of SDD or try the datapath command to see if it supports turning this feature off.
If you've used both SDD and SDDPCM, you'll remember that with SDD, each LUN has a corresponding vpath and an hdisk for each path to the vpath or LUN. And with SDDPCM, you just have one hdisk per LUN. Thus, with SDD one can submit queue_depth x # paths to a LUN, while with SDDPCM, one can only submit queue_depth IOs to the LUN. If you switch from SDD using 4 paths to SDDPCM, then you'd want to set the SDDPCM hdisks to 4x that of SDD hdisks for an equivalent effective queue depth. And migrating to SDDPCM is recommended as it's more strategic than SDD.
Both the hdisk and adapter drivers have an "in process" and "wait" queues. Once the queue limit is reached, the IOs wait until an IO completes, freeing up a slot in the service queue. The in process queue is also sometimes referred to as the "service" queue
It's worth mentioning, that many applications will not generate many in flight IOs, especially single threaded applications that don't use asynchronous IO. Applications that use asynchronous IO are likely to generate more in flight IOs.
What tools are available to monitor the queues?
For AIX, one can use iostat (at AIX 5.3 or later) and sar (5.1 or later) to monitor some of the queues. The iostat -D command generates output such as:

Here, the avgwqsz is the average wait queue size, and avgsqsz is the average service queue size. The average time spent in the wait queue is avgtime. The sqfull value has changed from initially being a count of the times we've submitted an IO to a full queue, to now where it's the rate of IOs submitted to a full queue. The example report shows the prior case (a count of IOs submitted to a full queue), while newer releases typically show decimal fractions indicating a rate. It's nice that iostat -D separates reads and writes, as we would expect the IO service times to be different when we have a disk subsystem with cache. The most useful report for tuning is just running "iostat -D" which shows statistics since system boot, assuming the system is configured to continuously maintain disk IO history (run # lsattr -El sys0, or smitty chgsys to see if the iostat attribute is set to true).
The sar -d command changed at AIX 5.3, and generates output such as:

The avwait and avserv are the average times spent in the wait queue and service queue respectively. And avserv here would correspond to avgserv in the iostat output. The avque value changed; at AIX 5.3, it represents the average number of IOs in the wait queue, and prior to 5.3, it represents the average number of IOs in the service queue.
SDD provides the "datapath query devstats" and "datapath query adaptstats" commands to show hdisk and adapter queue statistics. SDDPCM similarly has "pcmpath query devstats" and "pcmpath query adaptstats". You can refer to the SDD manual for syntax, options and explanations of all the fields. Here's some devstats output for a single LUN:

Here, we're mainly interested in the Maximum field which indicates the maximum number of IOs submitted to the device since system boot. Note that Maximum for devstats will not exceed queue_depth x # paths for SDD when qdepth_enable=yes. But Maximum for adaptstats can exceed num_cmd_elems as it represents the maximum number of IOs submitted to the adapter driver and includes IOs for both the service and wait queues. If, in this case, we have 2 paths and are using the default queue_depth of 20, then the 40 indicates we've filled the queue at least once and increasing queue_depth can help performance. For SDDPCM, if the Maximum value equals the hdisk's queue_depth, then the hdisk driver queue was filled during the interval, and increasing queue_depth is usually appropriate.
One can similarly monitor adapter queues and IOPS: for adapter IOPS, run # iostat -at <# of intervals> and for adapter queue information, run # iostat -aD, optionally with an interval and number of intervals.
How to tune
First, one should not indiscriminately just increase these values. It's possible to overload the disk subsystem or cause problems with device configuration at boot. So the approach of adding up the hdisk's queue_depths and using that to determine the num_cmd_elems isn't wise. Instead, it's better to use the maximum IOs to each device for tuning. When you increase the queue_depths and number of in flight IOs that are sent to the disk subsystem, the IO service times are likely to increase, but throughput will increase. If IO service times start approaching the disk timeout value, then you're submitting more IOs than the disk subsystem can handle. If you start seeing IO timeouts and errors in the error log indicating problems completing IOs, then this is the time to look for hardware problems or to make the pipe smaller.
A good general rule for tuning queue_depths, is that one can increase queue_depths until IO service times start exceeding 15 ms for small random reads or writes or one isn't filling the queues. Once IO service times start increasing, we've pushed the bottleneck from the AIX disk and adapter queues to the disk subsystem. Two approaches to tuning queue depth are 1) use your application and tune the queues from that or 2) use a test tool to see what the disk subsystem can handle and tune the queues from that based on what the disk subsystem can handle. The ndisk tool (part of the nstress package available on the internet at http://www-941.ibm.com/collaboration/wiki/display/WikiPtype/nstress) can be used to stress the disk subsystem to see what it can handle. The author's preference is to tune based on your application IO requirements, especially when the disk is shared with other servers.
Caches will affect your IO service times and testing results. Read cache hit rates typically increase the second time you run a test and affect repeatability of the results. Write cache helps performance until, and if, the write caches fill up at which time performance goes down, so longer running tests with high write rates can show a drop in performance over time. For read cache either prime the cache (preferably) or flush the cache. And for write caches, consider monitoring the cache to see if it fills up and run your tests long enough to see if the cache continues to fill up faster than the data can be off loaded to disk. Another issue when tuning and using shared disk subsystems, is that IO from the other servers will also affect repeatability.
Examining the devstats, if you see that for SDD, the Maximum field = queue_depth x # paths and qdepth_enable=yes, then this indicates that increasing the queue_depth for the hdisks may help performance - at least the IOs will queue on the disk subsystem rather than in AIX. It's reasonable to increase queue depths about 50% at a time.
Regarding the qdepth_enable parameter, the default is yes which essentially has SDD handling the IOs beyond queue_depth for the underlying hdisks. Setting it to no results in the hdisk device driver handling them in it's wait queue. In other words, with qdepth_enable=yes, SDD handles the wait queue, otherwise the hdisk device driver handles the wait queue. There are error handling benefits to allowing SDD to handle these IOs, e.g., if using LVM mirroring across two ESSs. With heavy IO loads and a lot of queueing in SDD (when qdepth_enable=yes) it's more efficient to allow the hdisk device drivers to handle relatively shorter wait queues rather than SDD handling a very long wait queue by setting qdepth_enable=no. In other words, SDD's queue handling is single threaded where there's a thread for handling each hdisk's queue. So if error handling is of primary importance (e.g. when LVM mirroring across disk subsystems) then leave qdepth_enable=yes. Otherwise, setting qdepth_enable=no more efficiently handles the wait queues when they are long. Note that one should set the qdepth_enable parameter via the datapath command as it's a dynamic change that way (using chdev is not dynamic for this parameter).
If error handling is of concern, then it's also advisable, assuming the disk is SAN switch attached, to set the fscsi device attribute fc_err_recov to fast_fail rather than the default of delayed_fail. And if making that change, I also recommend changing the fscsi device dyntrk attribute to yes rather than the default of no. These attributes assume a SAN switch that supports this feature.
For the adapters, look at the adaptstats column. And set num_cmd_elems=Maximum or 200 whichever is greater. Unlike devstats with qdepth_enable=yes, Maximum for adaptstats can exceed num_cmd_elems.
Then after running your application during peak IO periods look at the statistics and tune again.
It's also reasonable to use the iostat -D command or sar -d to provide an indication if the queue_depths need to be increased.
The downside of setting queue depths too high, is that the disk subsystem won't be able to handle the IO requests in a timely fashion, and may even reject the IO or just ignore it. This can result in an IO time out, and IO error recovery code will be called. This isn't a desirable situation, as the CPU ends up doing more work to handle IOs than necessary. If the IO eventually fails, then this can lead to an application crash or worse.
Queue depths with VIO
When using VIO, one configures VSCSI adapters (for each virtual adapter in a VIOS, known as a vhost device, there will be a matching VSCSI adapter in a VIOC). These adapters have a fixed queue depth that varies depending on how many VSCSI LUNs are configured for the adapter. There are 512 command elements of which 2 are used by the adapter, 3 are reserved for each VSCSI LUN for error recovery and the rest are used for IO requests. Thus, with the default queue_depth of 3 for VSCSI LUNs, that allows for up to 85 LUNs to use an adapter: (512 - 2) / (3 + 3) = 85 rounding down. So if we need higher queue depths for the devices, then the number of LUNs per adapter is reduced. E.G., if we want to use a queue_depth of 25, that allows 510/28= 18 LUNs. We can configure multiple VSCSI adapters to handle many LUNs with high queue depths. each requiring additional memory. One may have more than one VSCSI adapter on a VIOC connected to the same VIOS if you need more bandwidth.
Also, one should set the queue_depth attribute on the VIOC's hdisk to match that of the mapped hdisk's queue_depth on the VIOS.
For a formula, the maximum number of LUNs per virtual SCSI adapter (vhost on the VIOS or vscsi on the VIOC) is =INT(510/(Q+3)) where Q is the queue_depth of all the LUNs (assuming they are all the same).
Note that to change the queue_depth on an hdisk at the VIOS requires that we unmap the disk from the VIOC and remap it back.
If using NPIV, then if you increase num_cmd_elems on the virtual FC (vFC) adapter, then you should also increase the setting on the real FC adapter.
A special note on the FC adapter max_xfer_size attribute
This attribute for the fscsi device, which controls the maximum IO size the adapter device driver will handle, also controls a memory area used by the adapter for data transfers. When the default value is used (max_xfer_size=0x100000) the memory area is 16 MB in size. When setting this attribute to any other allowable value (say 0x200000) then the memory area is 128 MB in size. At AIX 6.1 TL2 or later a change was made for virtual FC adapters so the DMA memory area is always 128 MB even with the default max_xfer_size. This memory area is a DMA memory area, but it is different than the DMA memory area controlled by the lg_term_dma attribute (which is used for IO control). The default value for lg_term_dma of 0x800000 is usually adequate.
So for heavy IO and especially for large IOs (such as for backups) it's recommended to set max_xfer_size=0x200000 for AIX levels earlier than AIX 6.1 TL2.
The fcstat command can also be used to examine whether or not increasing num_cmd_elems or max_xfer_size could increase performance

This shows an example of an adapter that has sufficient values for num_cmd_elems and max_xfer_size. Non zero value would indicate a situation in which IOs queued at the adapter due to lack of resources, and increasing num_cmd_elems and max_xfer_size would be appropriate.
Note that changing max_xfer_size uses memory in the PCI Host Bridge chips attached to the PCI slots. The salesmanual, regarding the dual port 4 Gbps PCI-X FC adapter states that "If placed in a PCI-X slot rated as SDR compatible and/or has the slot speed of 133 MHz, the AIX value of the max_xfer_size must be kept at the default setting of 0x100000 (1 megabyte) when both ports are in use. The architecture of the DMA buffer for these slots does not accommodate larger max_xfer_size settings"
If there are too many FC adapters and too many LUNs attached to the adapter, this will lead to issues configuring the LUNs. Errors will look like:
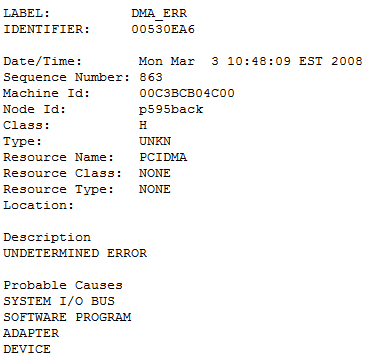
Recommended Actions
PERFORM PROBLEM DETERMINATION PROCEDURES

So if you get these errors, you'll need to change the max_xfer_size back to the default value. Also note that if you are booting from SAN, if you encounter this error, you won't be able to boot, so be sure to have a back out plan if you plan to change this and are booting from SAN.
